Unified Virtual Addressing
Unified Virtual Addressing, or UVA, provides a single virtual memory address space for all memory in the system, and enables pointers to be accessed from GPU code no matter where in the system they reside, whether its device memory (on the same or a different GPU), host memory, or on-chip shared memory. It also allows cudaMemcpy to be used without specifying where exactly the input and output parameters reside. UVA enables “Zero-Copy” memory, which is pinned host memory accessible by device code directly, over PCI-Express, without a memcpy. Zero-Copy provides some of the convenience of Unified Memory, but none of the performance, because it is always accessed with PCI-Express’s low bandwidth and high latency.
UVA requires the application runs as 64-bit process, and GPU's compute ability is 2.0 or higher.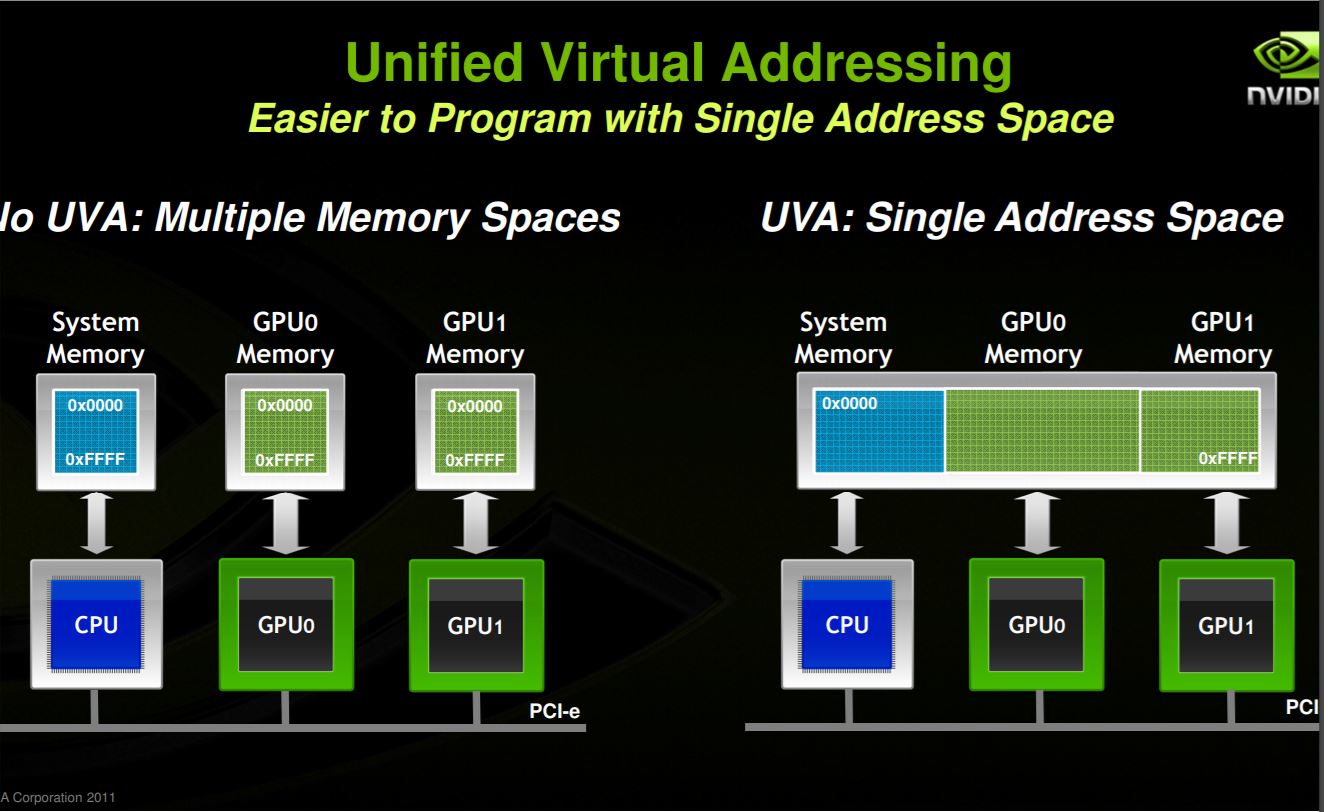 The difference between Unified Memory and
The difference between Unified Memory and UVA is:
UVA does not automatically migrate data from one physical location to another, like Unified Memory does. Because Unified Memory is able to automatically migrate data at the level of individual pages between host and device memory, it required significant engineering to build, since it requires new functionality in the CUDA runtime, the device driver, and even in the OS kernel.
References:
Unified Memory in CUDA 6;
Peer-to-Peer & Unified Virtual Addressing.