CUDA Programming model
The canonical CUDA programming model is like following:
- Declare and allocate host and device memory.
- Initialize host data.
- Transfer data from the host to the device.
- Execute one or more kernels.
- Transfer results from the device to the host.
- Free host and device memory.
The example is like this (the code is from An Easy Introduction to CUDA C and C++):
#include <stdio.h>
__global__
void saxpy(int n, float a, float *x, float *y)
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) y[i] = a*x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y, *d_x, *d_y;
x = (float*)malloc(N*sizeof(float));
y = (float*)malloc(N*sizeof(float));
cudaMalloc(&d_x, N*sizeof(float));
cudaMalloc(&d_y, N*sizeof(float));
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
cudaMemcpy(d_x, x, N*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, N*sizeof(float), cudaMemcpyHostToDevice);
// Perform SAXPY on 1M elements
saxpy<<<(N+255)/256, 256>>>(N, 2.0f, d_x, d_y);
cudaMemcpy(y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost);
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = max(maxError, abs(y[i]-4.0f));
printf("Max error: %f\n", maxError);
cudaFree(d_x);
cudaFree(d_y);
free(x);
free(y);
}
But since CUDA 6 introduced Unified Memory (the image is from Unified Memory in CUDA 6):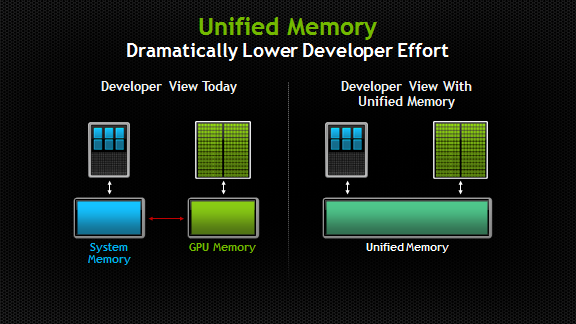
This means allocating memory in the GPU, but both CPU and GPU code can access the memory directly, no need to copy back and forth. The CUDA programming model becomes:
- Declare and allocate device memory.
- Initialize device data.
- Execute one or more kernels.
- Free device memory.
Check following code (the code is from An Even Easier Introduction to CUDA):
#include <iostream>
#include <math.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
add<<<1, 1>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
You can see there is no long "cudaMemcpy". You can replace
add<<<1, 1>>>(N, x, y);
by following code:
for (int i = 0; i < N; i++) {
y[i] = x[i] + y[i];
}
Even use OpenMP:
#pragma omp parallel for
for (int i = 0; i < N; i++) {
y[i] = x[i] + y[i];
}
References:
An Easy Introduction to CUDA C and C++;
An Even Easier Introduction to CUDA;
Unified Memory in CUDA 6.